



今トレンドのIoT。でも手に入れたデータで何をする?
センサーの小型化や高性能化、ネットワークのコスト削減が進み、今では現実的なレベルでインターネットに接続されたモノとデータをやりとりすること、いわゆるIoT (Internet of Things)を実現できるようになり、以前はデータとして捉えられなかった様々なモノをデータソースとして考えられるようになりました。また今ではiPhoneやAndroidといったモバイルデバイスの高性能化に伴って、私たちはより多くの用途で、より多くの時間に、より多くのデータを作り出しています。
例えば一度食事に出ればGPSデータを利用してお店にチェックインし、写真を撮影してソーシャルネットワークへ投稿、クレジットカードで決済して、口コミサイトにお店のレビューを投稿するかもしれません。どの行為もネットワークを通して、新しいデータをネットワーク上に作成しています。
実際に世界中のデータは爆発的に増え続けていて、例えばFacebookだけを見ても1日あたりに作成される写真や位置情報などのデータは500,000GBに達しているそうです。

しかし、日々このように様々なシチュエーションで増え続け保存されているデータを企業はどれぐらい活用出来ているでしょうか?
増え続けるデータを利用し、成果を出すことはそう簡単ではありません。Boston Consulting Groupによると、銀行が保有する莫大な量のデータのうち、3分の1は全く活用されていないという調査結果もあるぐらいです。データを集めることは重要ですが、データはただ持っているだけでは意味がなく、どうやってそれを分析し、活用するかを考える必要があります。
そこで重要になってくるのがデータとインテリジェンスという考え方です。
インテリジェンスとは?
Salesforce を利用していたり、Salesforce 上で開発を行っている皆さんはビジネス・インテリジェンス(BI)という言葉自体は聞いた事があると思います。しかし、この意味を明確に理解しているという方は意外と少ないのではないでしょうか?
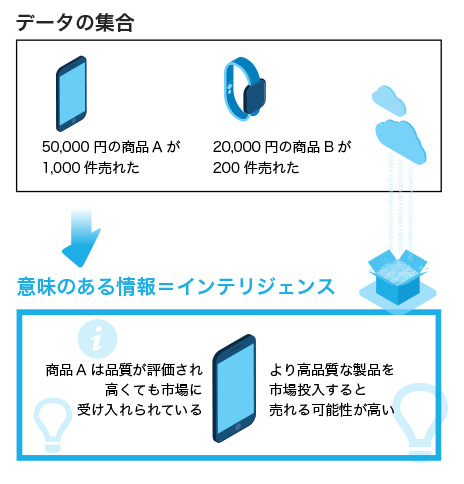
BIとは「事実に基づくデータを元にして分析を行い、ビジネス上の意思決定を行うための概念と手法」ですが、この意思決定を行うために必要な「情報」がインテリジェンスです。データはそのままでは単なる事実の集合でしかないので、そこから意味のある結果を導き出さなければなりません。
例えば「3000円の商品Aが1000件売れた」「500円の商品Bは500件売れた」「ソーシャルメディアでのLike数」というのはデータの集合ですが、「商品Aは品質が評価され高くても市場に受け入れられている」「より高品質な製品を市場投入すると売れる可能性が高い」という分析の結果が意味のある情報「= インテリジェンス」となります。
ここで重要となるのが、データの質と試行錯誤の回数です。
いかにすぐれたツールやデータサイエンティストが居ても、元となるデータが足りていなかったり、正確でない場合には正しいインテリジェンスを得ることは出来ません。またインテリジェンスは単一の観点から出た分析結果だけでは得ることができません。様々な観点から、データに対する分析の試行錯誤を繰り返すことで、ビジネス上の傾向や課題が見えてくる可能性がより高まります。
データを価値あるインテリジェンスに変えるための5つのステップ
では実際にやってみようと思っても、やみくもに設計をしては正しいインテリジェンスを得られません。幾つかの重要なトピックを、順序立てて考える必要があります。
そこで、ビッグデータやIoTなどのデータを活用し、その先のインテリジェンスを得るために考慮すべき5つのステップをご紹介します。
1. データソースの整理
スマートフォンによって人の位置情報が統計可能なデータに変わったように、IoTによって今まではデータとして捉えられなかったあらゆるものがデータソースとして考えられるようになりました。センサーからは温度や湿度から、揺れ・傾き・加速度や音量、加重、光度など様々な要素を取得することができますし、モバイル・デバイスからもユーザ自身の入力以外にGPSやジャイロセンサーといった情報が取得できます。
どんなモノにセンサーをつければどのようなデータを取得できるのかをまず確認します。全ての情報を取得できればベストですが情報の種類が多ければ多いほど、通信されるデータの量、センサーのコストや物理的なサイズ、そして消費電力は増える傾向にあります。もちろん受け取り側の設備もデータの通信サイズや通信頻度によって増強の必要が出てきます。得たいインテリジェンスにとって必要、あるいは利用する可能性が高いデータは何かを整理します。
2. データのキャプチャリング
基本的にセンサーやデバイスで発生した信号は、何らかのAPIを介してネットワーク上のサーバにメッセージを送るわけですが、必ずしもインターネットで一般的なHTTPプロトコルを利用できるとも限りません。むしろセンサーデバイスからの通信の場合、軽量かつQoSやWillなどの機能があるMQTTプロトコルが好まれる傾向もあります。
このようにHTTP以外の通信の場合には、それらを解釈し、場合によってはHTTPへ変換するブローカーサービスが必要になるでしょう。データソースから通信されるプロトコル理解しキャプチャリングと変換を行えるブローカサービスを準備します。
3. データ処理の準備
受け取ったデータはその意味を理解しなければ活用できません。次にデータ処理やフィルタリングを行うテクノロジを選定しておきます。
データの処理には、蓄積された大量のデータに対して行うものと、データストリームに対してリアルタイムに処理を行うものの2種類が存在し、従来のシステムとは違ったアプローチがそれぞれ必要となります。蓄積された大量のデータを処理するには、従来のSQLを利用したリレーショナルデータベースは適しません。大量のデータ・セットを格納、処理できる専用のテクノロジーを準備しておきます。
前出のキャプチャリングのステップとも共通しますが、データのキャプチャ失敗や永続化の失敗・データのロストが増えることは、データの品質が低下し、正しいインテリジェンスを得にくくなることを意味します。処理のパフォーマンスと共に信頼性も重要視してテクノロジーを選択しましょう。一方リアルタイムのデータストリームの解釈では、流れてくるデータを一定の条件に従って処理する高速なルールエンジンを準備し、あらかじめルールを定義しておく必要があります。
例えば、センサーを組み込んだ自社の製品がある一定温度を超えたら異常検知としてアラートを緊急時担当のチームに報告するなど、想定されるケースをあらかじめ決めておきましょう。
4. 分析とエンタープライズデータとの融合
IoTなどのデバイスからのデータ活用で間違いがちなのは、膨大なストリームデータ「のみから」ビジネスに役立つインテリジェンスを得ようとする事です。実際にはデバイスだけでなく、デバイスに紐づく顧客データとの組み合わせからデータを割り出す事も少なくありません。
例えば「店頭のiBeaconセンサーに反応した顧客(= 店頭によく来る顧客)と購買傾向の相関関係」などは、CRM上の購買履歴データとセンサー情報の組み合わせによって得ることができるインテリジェンスの1つです。また、前出の通りインテリジェンスを得るには分析の試行錯誤の回数が重要となります。
データ分析のアイデアが頭にうかんだ際に、素早く簡単に条件を変更できるサービスを利用することで、試行錯誤の回数と継続が行えるでしょう。データを簡単に素早く分析でき、従来のエンタープライズシステムにあるデータをシームレスに取り込めるサービスを選定しましょう。
5. 成果とアクション
最後に成果を抽出し、展開する方法について準備しておきます。
分析自体がゴールではなく、最終的にはビジネスに何らかの気づきや改善を与えることが目的ですので、得たインテリジェンスを営業部門や製品開発部門など関係者に伝える必要があります。
インテリジェンスを活用するためのサービスには、得たインテリジェンスを関係者に共有し、場合によってはアクションを起こすためのディスカッションの場を用意したり、タスクフォースを編成する事も必要になってきます。可能な限り、分析ツールと情報共有基盤がシームレスに統合したサービスの利用が望ましいでしょう。
いかがでしょうか?
このように5つのステップに沿ってインテリジェンス得るための設計を行うことで、IoTを含めた様々なデータを活用できるようになります。
また、インテリジェンスを得るために重要なトピックをホワイトペーパーにしてご用意しました。ぜひこちらも合わせてご覧下さい。


