
Data Warehouse y Data Lake:
¿Cuáles son las diferencias?
En el contexto de la transformación digital en las empresas, la inteligencia analítica se ha convertido en uno de los principales pilares de la gestión estratégica. Especialmente en la última década, el análisis de big data se ha desarrollado para mantenerse al día con los rápidos cambios del mercado – provocado, entre otros fenómenos, por el crecimiento de las redes sociales, el e-commerce y la tecnología móvil.
A cargo de administrar y analizar los datos corporativos, los equipos de analytics y big data buscan fomentar negocios competitivos y “preparados para el futuro”. Para que esto suceda, cuentan con tecnologías cada vez más sofisticadas para el almacenamiento y procesamiento de datos. Los data warehouses y data lakes se encuentran entre las opciones más populares en este sentido, cada uno con una arquitectura y un propósito específicos.
En este artículo, aprenderemos más sobre estas soluciones, cubriendo puntos como:
- ¿Qué son los data warehouses y data lakes?
- ¿Cuáles son las principales diferencias entre estas estructuras?
- ¿Cómo funciona cada repositorio?
- ¿Cómo encajan los data warehouses y data lakes en la rutina de business intelligence (BI)?
A partir de esta introducción, tendrás insumos para iniciar o mejorar proyectos de big data en tu empresa, satisfaciendo las principales necesidades de tu negocio y obteniendo el máximo valor de los datos recopilados.
¿Listo para mejorar tus procesos de gestión de datos? ¡Sigue leyendo y compruébalo!
Clasificación e Integración de Datos
Antes de presentar los data warehouses y data lakes, debemos hablar sobre las categorías de datos y ETL, el principal proceso de integración de datos digitales.
Tipos de Datos
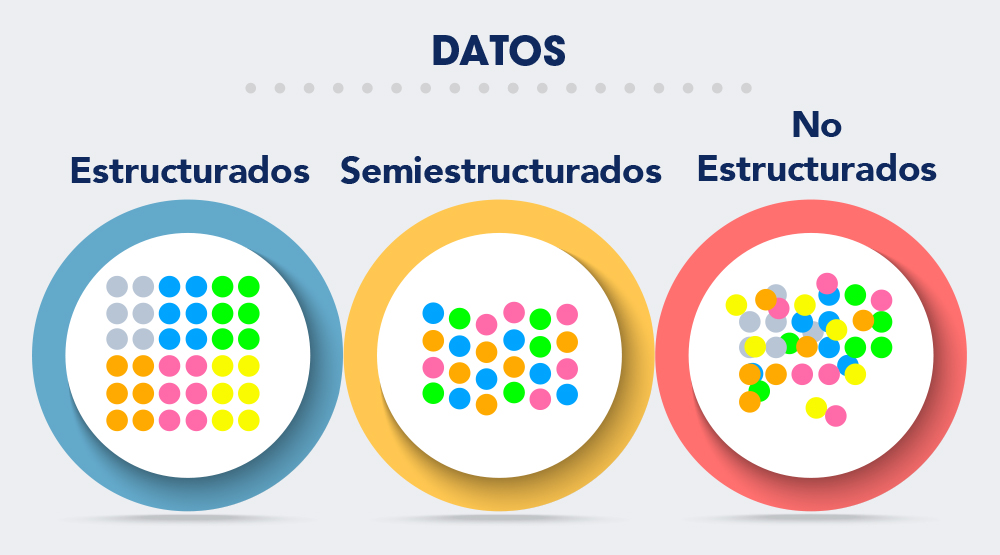
Los datos disponibles en la web se dividen hoy en tres categorías:
Datos Estructurados
Son datos formateados según parámetros específicos, para organización en esquemas relacionales. Uno de los principales formatos de datos estructurados son las tablas, que se distribuyen en filas y columnas con valores predeterminados.
Ejemplos: hojas de cálculo y bases de datos (Excel, CSV, SQL, archivos JSON, entre otros).
Datos Semiestructurados
Como su nombre indica, se dan con cierta organización interna, pero no están del todo estructurados.
Ejemplos: archivos web (HTML, XML, OWL, entre otros).
Datos no Estructurados
Son datos sin una organización o jerarquía interna clara. Es la categoría más amplia y cubre la mayor parte de los datos de la web.
Ejemplos: documentos de texto (archivos Word, PDF), archivos multimedia (imagen, audio y video), correos electrónicos, mensajes de texto, datos de redes sociales, dispositivos móviles, Internet de las cosas (IoT), entre otros.
ETL
En inglés, ETL es un acrónimo de Extract (Extraer), Transform (Transformar) y Load (Cargar).
ETL es el método más tradicional de integración de datos digitales, y cada término del acrónimo designa un paso en el proceso. Mira la infografía y lee más a continuación:
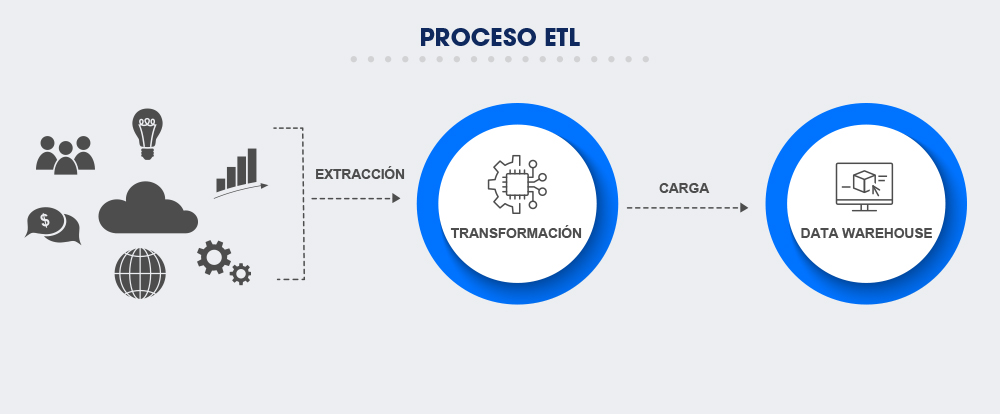
ETL: ¿Cómo funciona el proceso?
- Extracción (E): en esta fase, los datos se recolectan de diferentes sistemas organizacionales y se llevan a un espacio temporal (staging area), donde se convierten al mismo formato para transformación.
- Transformación (T): los datos brutos se pulen y estandarizan según las necesidades de la empresa. Al final de esta etapa, los datos están "limpios", estructurados y listos para el almacenamiento.
- Carga (L): los datos procesados se envían a un repositorio específico, donde se almacenarán de forma segura y se activarán para consulta interna.
Desde finales de la década de 1970, cuando ETL se hizo popular, ha estructurado datos para su almacenamiento en bancos como data warehouses. ¿Vamos a saber más sobre estos repositorios?
Data Warehouse
Como literales "almacenes de datos", los data warehouses recopilan datos históricos para clasificarlos en bloques semánticos, llamados relaciones. Por esta razón, el data warehouse es una base de datos relacional, que contiene principalmente datos estructurados.
Los datos del data warehouse se distribuyen en subconjuntos denominados data marts ("mercados de datos"), que aceleran la recuperación y la entrega de datos a equipos específicos. Una vez solicitados, los datos del data warehouse se ponen a disposición en modo lectura, de acuerdo con la demanda de los analistas de big data y BI.
Unificados, libres de desviaciones e inconsistencias, los datos del data warehouse producen análisis altamente precisos que, a su vez, generan información e insights estratégicos. En resumen, por lo tanto: los data warehouses centralizan los datos relevantes para la empresa, sistematizándolos de manera eficiente y apoyando la creación de estrategias comerciales basadas en data-driven.
Con una cuidadosa planificación y ETL, los data warehouses agregan un enorme valor a las decisiones organizacionales, siendo estructuras que permiten la optimización y aplicación práctica de los datos almacenados.
Big Data y la Revolución de los Datos
Desde la década de 1990, el uso comercial y doméstico de Internet ha despegado, acelerando la generación de datos y el tráfico en la web. Este fenómeno dio lugar al concepto de big data, revelando también las limitaciones del data warehouses y repositorios relacionados, como las bases de datos (databases).
Al tratar con datos de volumen, velocidad y una variedad sin precedentes (las 3 Vs del big data), los gerentes de tecnología previeron el colapso de los sistemas tradicionales de gestión de la información. La transformación de datos para uso corporativo se convirtió en una operación muy costosa: primero, porque requería miles de terabytes de almacenamiento (datos que no siempre eran relevantes). En segundo lugar, porque requiere cada vez más tiempo de equipos dedicados, lo que requiere, por supuesto, mano de obra calificada.
Por lo tanto, hacer que la gestión de datos sea más eficiente, segura y económicamente sostenible era un desafío urgente para las empresas. A principios de la década de 2000, surgieron los primeros prototipos de una solución innovadora: el data lake.
Data Lake
¿Qué te viene a la mente cuando piensas en un lago? Quizás la idea de un gran tanque natural, cuya agua se pueda filtrar para abastecer su entorno. Esta metáfora, creada por James Dixon, uno de los fundadores de Pentaho, ayuda a comprender el concepto de data lake (“lago” o depósito de datos).
A diferencia del data warehouse, el data lake es una base de datos no relacional. Es decir: es un repositorio que no requiere estructuración previa de datos, en el que “fluye” en su formato original (estructurado, semiestructurado o no estructurado).
Una vez derivados de los sistemas y aplicaciones corporativos, los datos se llevan al data lake "saltando" la etapa T de ETL (transformación). Sin este tratamiento, el repositorio almacena gigantescos volúmenes de datos de cualquier tipo y escala, alcanzando cientos de petabytes (¡1 PB es más de mil terabytes!).
Si el data lake es una estructura tan robusta, ¿cuál es la ventaja de mantenerlo? Almacenar los datos en su totalidad y procesarlos bajo demanda, de forma escalable. El agua del lago, por ejemplo, se puede filtrar para abastecer un camión de agua o botellas de 500 ml. Asimismo, los datos del data lake (en gran parte no estructurados) son más flexibles, ya que no se han enmarcado en esquemas predefinidos.
Además de ahorrar tiempo y costos de almacenamiento, el data lake facilita la automatización de procesos y la innovación basada en datos, impulsando la transformación digital de las empresas. Los datos se pueden "personalizar" para proyectos en todas las áreas, además de la creación de algoritmos de deep learning. También se pueden estructurar para su asignación en data warehouses, donde se utilizarán en análisis estratégicos.
Los data lakes son manejados principalmente por ingenieros y científicos de datos, responsables de diseñar la estructura, integrarla en el flujo de datos general y curar la gran riqueza de datos derivados. En definitiva: es una solución que gestiona los datos de forma económica y dinámica, alineando la empresa con las tendencias del mercado contemporáneo.
Data Warehouse x Data Lake: ¿Cuál es la mejor opción?
Mientras ambos se prestan al almacenamiento y procesamiento de datos, los data warehouses y los data lakes se diferencian principalmente en cuatro aspectos: contenido, función, usuarios y tamaño. Vea la comparación abajo:
|
Data Warehouse |
Data Lake |
Contenido |
Datos estructurados |
Datos estructurados, semiestructurados y no estructurados |
Función |
Almacenar datos relevantes para la gestión estratégica |
Almacenar big data para obtener la mejor relación costo-beneficio |
Usuarios Principales |
Analistas de big data e inteligencia empresarial (BI) |
Científicos e ingenieros de datos |
Tamaño |
Requerido para almacenar datos relevantes para el análisis |
Requerido para almacenar todos los datos útiles (orden de petabytes) |
Para elegir la mejor opción para tu negocio, debes tener en cuenta criterios como el tamaño de la empresa, los objetivos y las limitaciones de tus proyectos de big data. ¿Cuál es tu prioridad en este momento: administrar los datos de manera más eficiente? ¿Obtener información de inteligencia de mercado? ¿O fortalecer el área de innovación y soluciones digitales?
Como regla general, los data lakes son adecuados para administrar datos no estructurados y los data warehouses son esenciales para el análisis a gran escala. Sin embargo, conviene recordar que los repositorios no son exclusivos. Al integrar el mismo flujo de administración de datos, los data warehouses y data lakes combinan ventajas como una mayor productividad, una mayor asertividad en el análisis y una mejor relación costo-beneficio.
Finalmente, otro punto a evaluar es el modelo de almacenamiento: local (on-premises), en la nube (cloud) o híbrido. El almacenamiento en la nube se ha vuelto popular por su escalabilidad y bajo costo, ya que no requiere integración con sistemas locales. Los ingenieros de datos y otros expertos pueden guiarte tú y a tu equipo para planificar el arreglo más seguro y funcional para tu empresa.
¿Respondemos tus preguntas sobre la gestión de datos?
La inteligencia analítica es una de las especialidades de Salesforce. Si este material fue útil para ti, ¡explora otro contenido sobre el tema en nuestro blog y Centro de recursos! Aprovecha la oportunidad de descubrir y experimentar Tableau, nuestra plataforma integrada de analytics y CRM. ¡Hasta la próxima!